Skill 写了总跑偏?先让 NotebookLM 理资料,再回 Claude Code 跑真任务
我把旧稿、删掉的标题、审校清单和失败输出一起喂给 NotebookLM,再回 Claude Code 跑真任务。Skill 真正有用的地方,不是把文件写满,而是把规则从失败里逼出来。
你写过skills吗?比如你要准备一篇文章,大模型却总是胡乱改你的表达,满篇的“不是……而是……、稳稳接住”,标题看着像样,就是读不懂,真要发布,自己还得从头到尾改一遍,比自己写还累。
如果你让大模型帮你写过东西,估计这些酸爽都遇到过。 大模型是厉害,脑子里装满了全世界的百科全书,但难就难在它在解决问题的时候,并不知道应该掏出脑子里哪个部分的知识。所以很多时候看起来像把事做完了,实际上只是把它认为对的东西,胡乱塞给你。 你说,帮我把标题改成30个字,简单啊,它给你一串自认为正确的关键词,说不定连语法都有问题。让它下一版别再写成教程腔,它只懂得把“第一、第二、第三、综上所述”从原文中去掉。让它少废话,它最后还可能回一句“整体不错”。
1 不急着写规则
问题不在于提示词写得不够长。 很多人用大模型干活,第一反应都是把提示词继续加长。你不听话,我就多写几句。你总跑偏,我就把要求写得更细。你喜欢写报告腔,我就补一句“要像人说话”。 这当然有用,但只能救你一次。 下一次换了任务,模型又开始猜。 你让它帮你写一篇公众号,它不知道哪些是你习惯的表达,哪些是你绝对不能接受的句式,哪些地方必须保留,哪些地方可以重写。 你让它整理资料,它也不知道你是想要一个摘要,还是想要一套完整知识库。 大模型最麻烦的地方就在这里:它会做一些它自认为正确的事。 你没说清楚的地方,它会替你补齐。你没定义标准的地方,它会按自己的标准定义。你说“帮我优化一下”,它就会把所有东西都往它认为完美的方向去做。 很多时候,我们可能就是想知道明天下不下雨。 而遇到稍微复杂一点的工作,仅仅是提示词就不够用了,这个时候就需要用skills。
2 Skills 解决什么?
skills就是一份大模型遵照的工作手册。
官方对Skills的解释很朴素:
建一个包含 SKILL.md 的文件夹,在里面写清楚这个能力什么时候触发、要读哪些参考文件、按什么步骤干活。大模型需要的时候加载它,不需要的时候就不占上下文。
它解决的就是:怎么把重复出现的工作,变成可复用的工作方式。
你要写公众号文章,当然不能只是一句“帮我写得有活人感”。
而是应该规定一系列的具体规则:
正文开头用什么格式,标题占不占用正文,正文内部不要靠空行制造节奏,不允许出现“压舱石、信息官、稳稳接住”这些词语,发布前还要做各种审校,等等。
如果每次都手打,根本不可能。
Skill可以把这些规则全部保存下来。
SKILL.md做入口,告诉模型什么时候用;reference 放长期规则;workflow 放执行步骤;review 清单专门负责检查中间执行有没有问题。
但是,Skills也不是万能的。很多Skill不好用,不是因为模型太弱,而是因为里面的规则本身就执行不了。
你说:“文章要有网感”。
模型说,懂了,然后给你写一堆“爆了、炸裂、全网都在看、惊天……”。
你说:“标题要吸引人”。
没问题,一通操作猛如虎,它会塞一堆热词,但标题读起来像营销号。
这些都不是模型不努力。
是你没有告诉它,怎样算做对,怎样算失败,失败以后要怎么改,臣妾做不到啊。
一个能用的 Skill,除了你让它要做到什么,还得有边界,有样例,有反例,有检查项。第一版写出来之后还不一定就用得顺手,是你使用过程中,不断根据问题,逐步添加信息,迭代出来的。
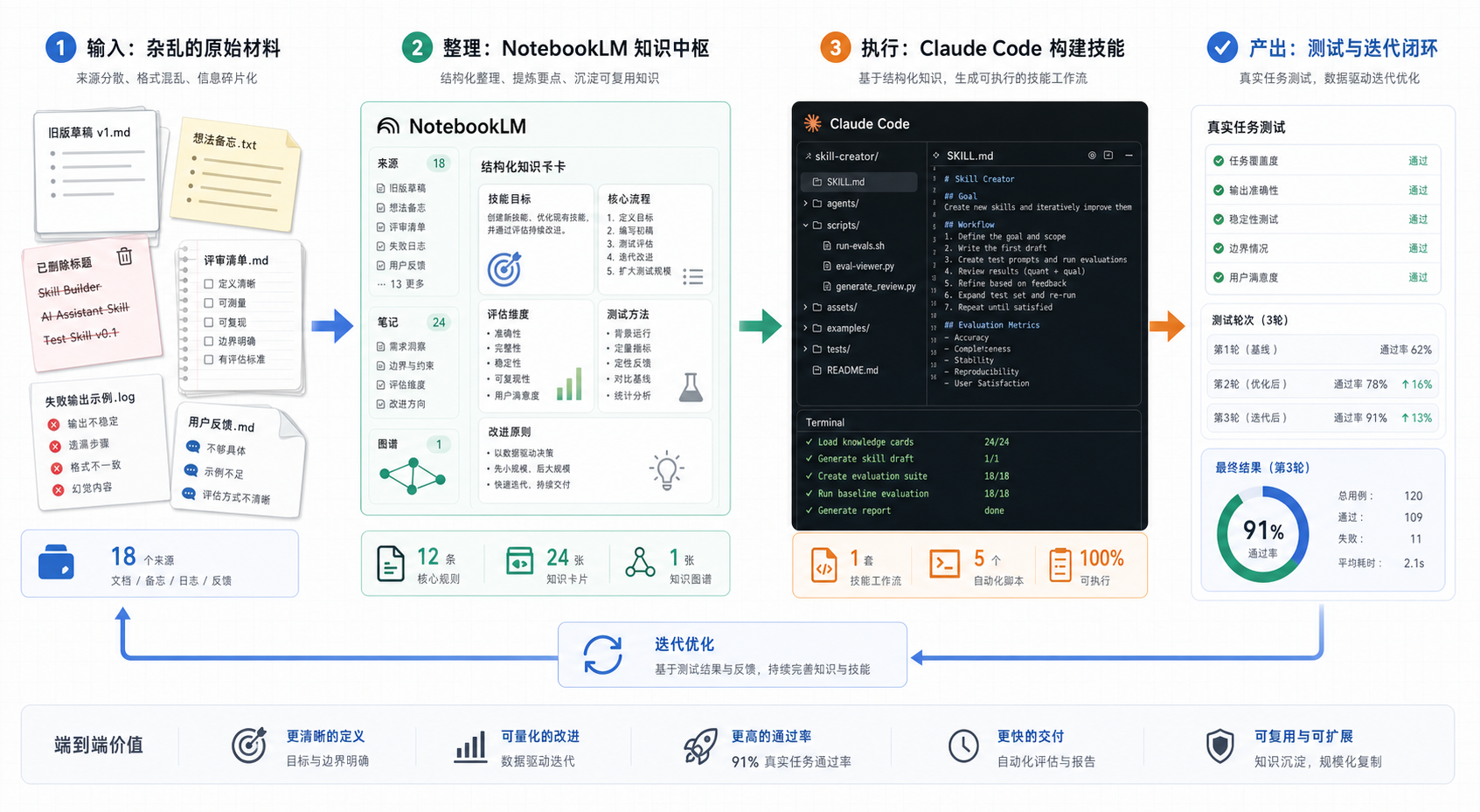
3 先让 NotebookLM 干粗活
好,具体应该怎么写出一条可用的skills?当然可以让大模型帮忙。
但很快你会发现,完全是开盲盒,claude写出来的东西有模有样,它会有目标、有流程、有注意事项、有输出格式,还有一堆悬挂缩进+无序列表,但问题是,真拿去跑任务,这玩意儿就是不听话。
偶然刷到Julian Goldie SEO的视频,里面有个思路很有价值,别一上来让大模型发明规则,先把材料喂给NotebookLM,让它整理出框架。
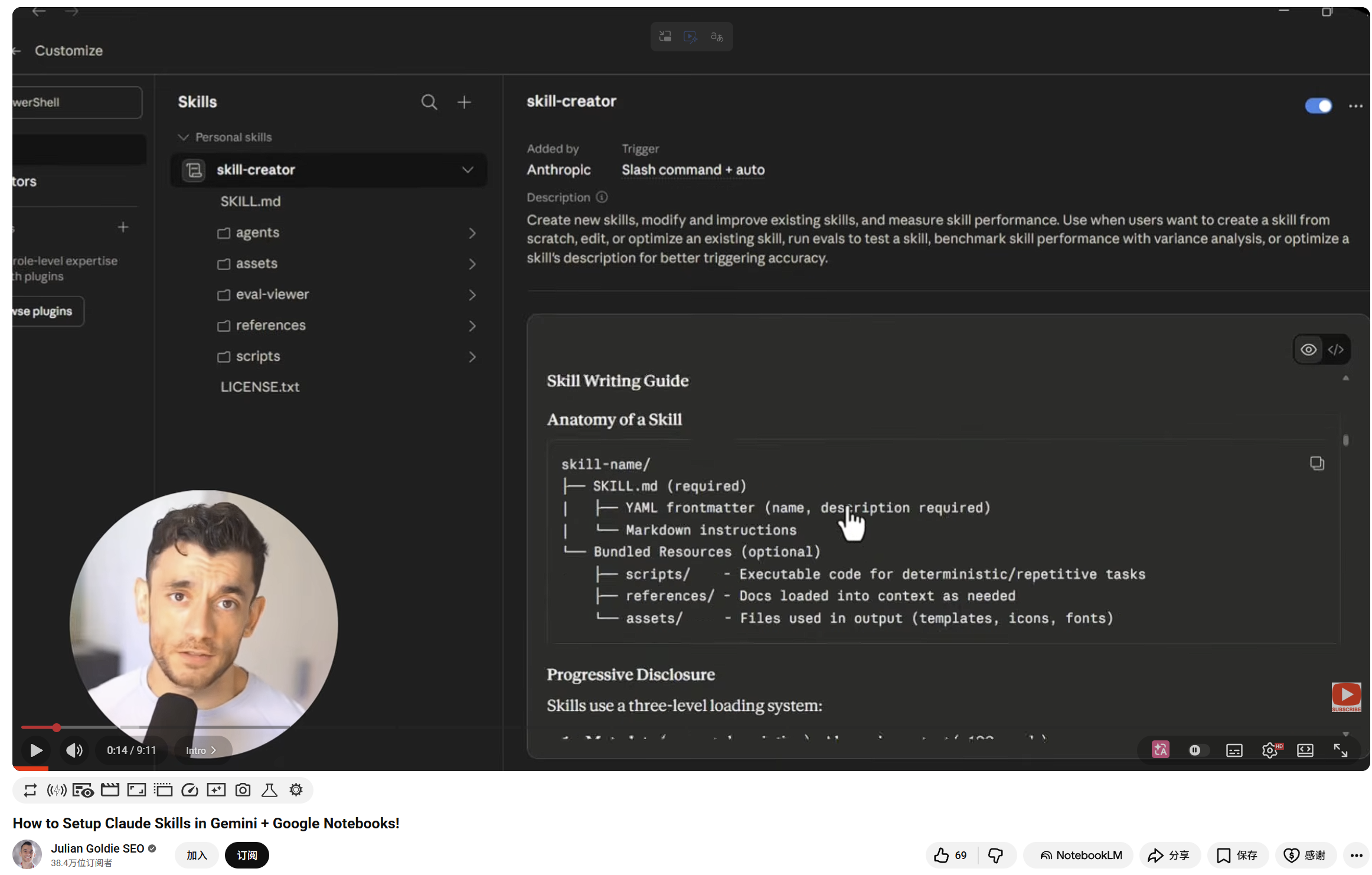 这一步就是关键。
Skill不要凭空写,它应该从你做过的事情里生长出来。
我自己的很多skills,在写的时候不仅会借鉴别人的一些好的思路,更会提前给notebookLM很多资料,比如自己的文章,清单,排版习惯,笔记等等。NotebookLM擅长整理,它能帮你归纳,哪些规则反复出现,哪些问题经常遇到,哪些表达是你不喜欢的,哪些步骤应该单独写成检查项……,这和直接问Claude完全不一样。
Claude 更像引擎,适合驱动任务。
这两个东西放在一起,刚好是绝配,NotebookLM先整理资料,Claude再负责执行和改造。一个像仓库,一个像施工队。仓库管理员不会去盖房子,施工队也没法空着手开工。
这一步就是关键。
Skill不要凭空写,它应该从你做过的事情里生长出来。
我自己的很多skills,在写的时候不仅会借鉴别人的一些好的思路,更会提前给notebookLM很多资料,比如自己的文章,清单,排版习惯,笔记等等。NotebookLM擅长整理,它能帮你归纳,哪些规则反复出现,哪些问题经常遇到,哪些表达是你不喜欢的,哪些步骤应该单独写成检查项……,这和直接问Claude完全不一样。
Claude 更像引擎,适合驱动任务。
这两个东西放在一起,刚好是绝配,NotebookLM先整理资料,Claude再负责执行和改造。一个像仓库,一个像施工队。仓库管理员不会去盖房子,施工队也没法空着手开工。
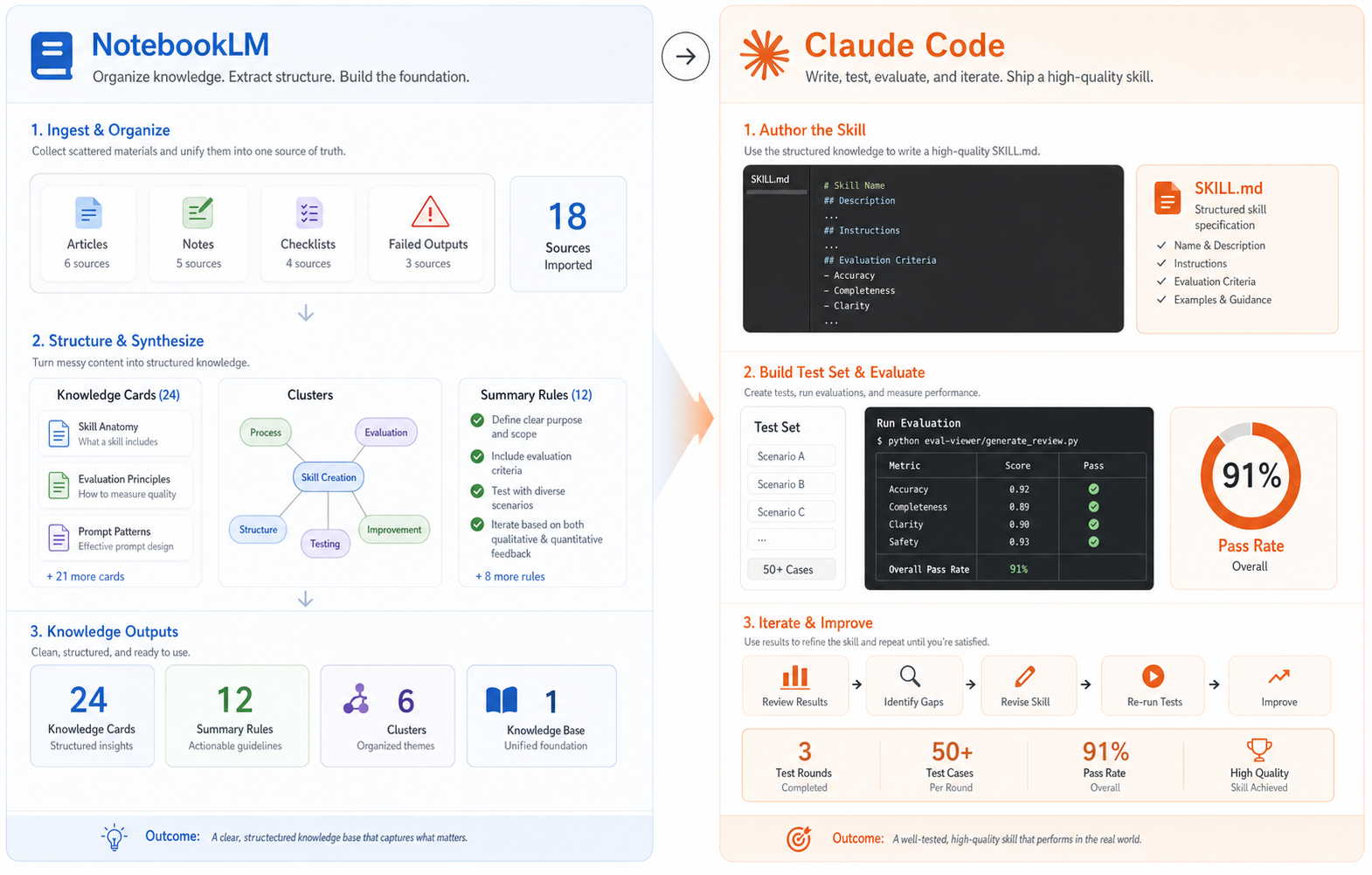
4 再用元 Skill 生成
真正要写一条skills的时候,必须还需要一个东西:skill-creator。
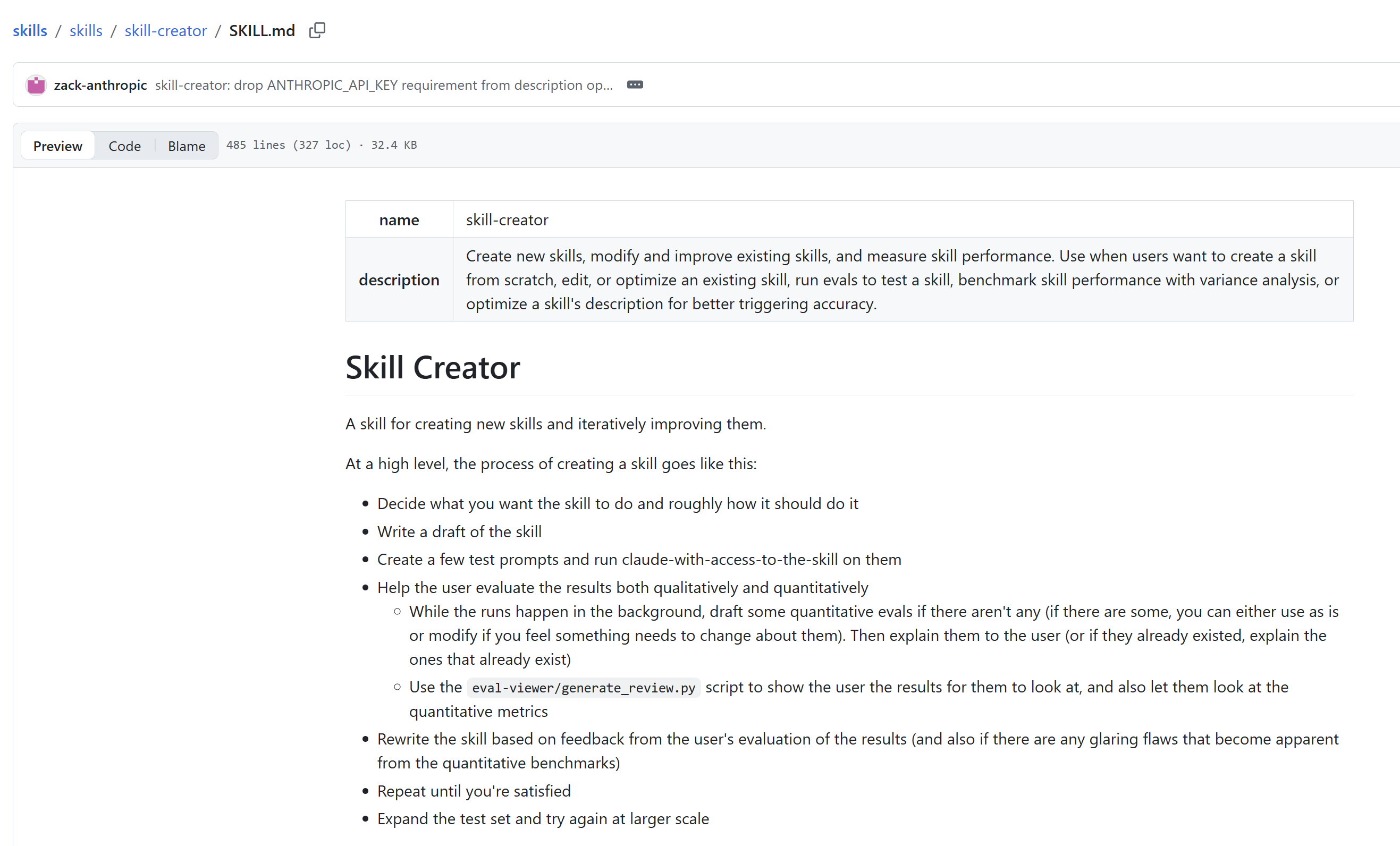 这是Claude官方发布的“生产skills的skills”,你把目标、材料、规则、触发场景告诉它,它来帮你搭 SKILL.md,拆 reference,整理目录,补上描述和执行步骤。
这一步也可能会迭代好几次。
第一版Skill,结果可能更像一份写作规范。里面有很多正确废话,比如“提升内容质量”“保持自然表达”“增强读者价值”。这些话都没错,可模型执行不了。
需要继续追问:
什么叫自然表达?哪些词不能出现?什么情况必须重写?正文能不能有空行?标题要多长?如果文章引用了别人的框架,要不要标来源?
这一轮问完,Skill才开始变得具体。
“避免 AI 味”,需要拆成很多条可量化,可检查的规则,比如:不要通篇单句成段,不要连续排比反问,“综上所述、值得注意的是、本质上”,尽量不出现,每篇文章至少要有两到三个实际的案例细节。
再往后,还要拆文件。
入口必须精简,否则每次加载都很重。详细的东西放到reference 里:内容原则一份,文章风格一份,生产工作流一份,去 AI 味审校一份。SKILL.md只负责告诉Claude什么时候读哪份材料,按照什么顺序干活。
这时候,一个 Skill 才像一个能用的工具,而不是一篇自我感动的说明书。
这是Claude官方发布的“生产skills的skills”,你把目标、材料、规则、触发场景告诉它,它来帮你搭 SKILL.md,拆 reference,整理目录,补上描述和执行步骤。
这一步也可能会迭代好几次。
第一版Skill,结果可能更像一份写作规范。里面有很多正确废话,比如“提升内容质量”“保持自然表达”“增强读者价值”。这些话都没错,可模型执行不了。
需要继续追问:
什么叫自然表达?哪些词不能出现?什么情况必须重写?正文能不能有空行?标题要多长?如果文章引用了别人的框架,要不要标来源?
这一轮问完,Skill才开始变得具体。
“避免 AI 味”,需要拆成很多条可量化,可检查的规则,比如:不要通篇单句成段,不要连续排比反问,“综上所述、值得注意的是、本质上”,尽量不出现,每篇文章至少要有两到三个实际的案例细节。
再往后,还要拆文件。
入口必须精简,否则每次加载都很重。详细的东西放到reference 里:内容原则一份,文章风格一份,生产工作流一份,去 AI 味审校一份。SKILL.md只负责告诉Claude什么时候读哪份材料,按照什么顺序干活。
这时候,一个 Skill 才像一个能用的工具,而不是一篇自我感动的说明书。
5 测试、测试、测试
软件工程里,写完功能不跑测试都是耍流氓。
Skill也一样。
你不能看它目录完整、文件齐全、描述漂亮,就觉得它能用了,必须拿真实任务去跑。
比如写文章,你告诉claude:
前面一段是我手写的,绝对不能动,后面有一堆备注,你仔细阅读体会,根据备注要求再修改原文,第一遍修改完之后,再次做几轮校验。
这几句话同时考了claude几件事,能不能识别用户的边界,能不能保留原文,能不能把备注改成正文,能不能控制引入顺序,能不能把抽象方法写成读者看得懂的过程,能不能在最后做风格审校。
这是Skill迭代的价值,每跑一个任务,就把失败变成新规则。保留原文失败,就加硬约束;标题太短,就加标题检查;正文太像报告,就重人味审校;总是漏掉来源,就把来源标注写进L0。
一个 Skill 的成熟,不是靠一次生成,而是靠一次次测出来。
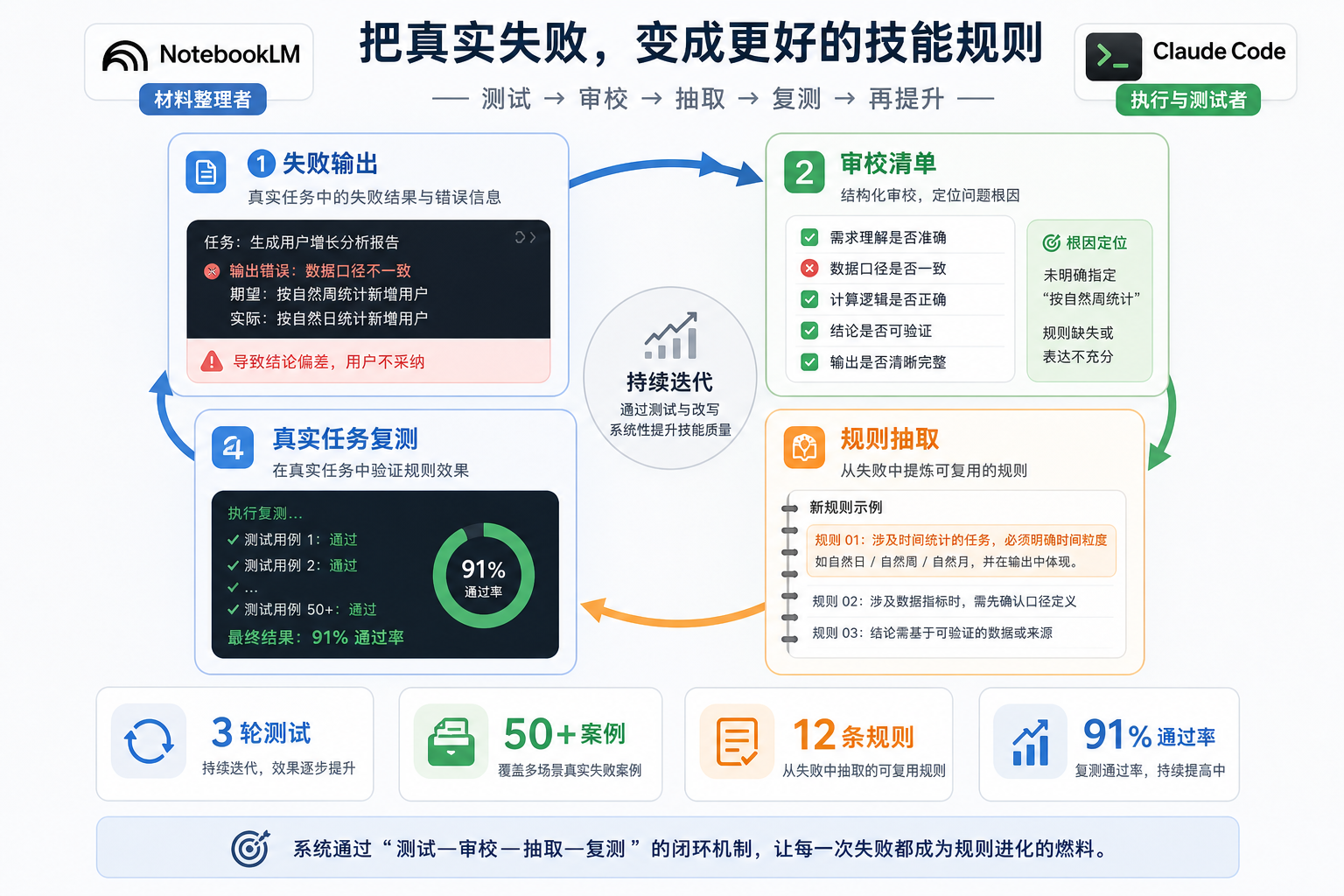
6 真正的差距
大模型和大模型不同。 NotebookLM负责把材料整理成可用的判断,Claude 负责驱动任务,creator-skills这类元工具负责把判断变成文件结构,最后再通过真实任务测试,把文件固化成稳定的工作流。 这些都不是某一个工具或某一轮聊天能完全做到的,这才是跟大模型交互的价值。 大模型有很多形态,聊天窗口是最常见的,类似claude code、antigravity、trae……这类IDE、CLI等形式,能操作文件和工具的又是一种,NotebookLM 这种围绕资料库工作的也是一种,专门跑审校的 Agent 又是另一种。 不会用大模型的人,不一定是不会提问。是他不知道什么场景该用什么形态。资料整理交给谁,执行任务交给谁,质量审校交给谁,长期规则沉淀在哪里,失败以后怎么回写到系统里。 只会聊天,当然也能得到答案。 但能把这些形态组织起来,才会形成自己的生产力。 Skills只是这个大系统的一个入口。 它把你反复说过的话、踩过的坑、坚持的判断,固定成一个模型能调用的工作方式。 所以它不是让大模型变聪明。它真正做的,是让大模型少猜一点,发挥出它该有的能力。 模型才会从一个会聊天的工具,慢慢变成你自己的生产系统。
<section style="margin: 28px 0 14px 0; text-align: center; color: #d46b2c; font-size: 15px; font-weight: 700; line-height: 1.8;"> 扫码直达 </section>